Cloud Native DevOps
I've recently finish another great read. This time the O'Reilly awesome book called Cloud Native DevOps. The authors are Justin Domingus and John Arundel. Let me first thank them for the awesome ride and also highly recommend this book.
The old good days
The book starts with an historical overview of what we now call of cloud.
The first chapter starts with this quote
There was never a time when the world began, because it goes round and round
like a circle, and there is no place on a circle where it begins.
And the idea is to remind us how the past keeps reinventing itself. The authors walk us way back into the ancient times of the cloud, which was in 1960. Yeah you read it right. The principle behind the modern cloud systems is basically a way to share computational resources for the sake of efficiency. Today when we deploy our apps in the cloud, being it AWS or GCP we are basically doing two things
- Buying time
- Using an infrastructure as a service
Guess what, this is what people did in 1960. In the book they put an image of an old mainframe IBM System/360 Model 91. This was a sleek start indeed.
From here the authors walk us again into the past. Now into the origins of DevOps. They remind for the old days when development was in one basket and operation teams in the other. This is usually refereed as an example of Conway's Law in Action a concept that was eloquently introduced by Eric Raymond seminal book New Hackers Dictionary with the following analogy
If you have four groups working on a compiler, you’ll get a 4-pass compiler
The issues that arise from two separated silos (dev and ops teams) sharing a single responsability (deliver good software to clients) was used to remind all of us how we come from It works on my machine way of doing things into the more modern approach of Infrastructure as Code.
From here the authors went into more present days and introduced two of the main problems of current modern software architectures
- How do you deploy and upgrade software across large, diverse networks of dif‐ ferent server architectures and operating systems?
- How do you deploy to distributed environments, in a reliable and reproducible way, using largely standardized components?
In the process of trying to solve these two previous points the authors make another great analogy. Actually this problem was already solved in another very different area of human enterprise, the transport industry. In the old times the transport of goods was something like a pain in the ass because we're missing a standard way of dealing with the transport of it. This became critically important when goods needed to be transferred between ships and terrestrial transportation. The lack of a standard introduced a lots of inefficiencies simply because you needed to
- Put the goods inside the ship
- Get the goods out of the ship into a truck
This was done in a good by good basis. How did they solve this? Yes you guess it with the Intermodal Container
Now replace ships by operating systems and goods by programs and you got the equivalent of an Intermodal Container. The Linux Container. Now, I believe, it is a little bit more obvious why this
![]()
is the Docker Logo
Now we got a container. So what I'm missing the ships, trucks and Port.
Yes, you guess it again. In this grand analogy Kubernetes is the Port we use to deploy our goods. Or maybe a ship if we take into account that this is the logo
![]()
Yes now we got the goods (our applications), the ship/port (kubernetes I mean). Now what? We need international standards right? Imagine that you build ad hoc ship and try to use an international Port. Yeah that wouldn't work right? The ship need to have to be build in a standard way for the port machinery to operate on it. You need to have
some specific dimensions to able to pass the not so profound waters and you need to have specialized radio protocols to communicate with the center to know exactly when to enter the port. Yeah fucking reality. Always more complex than we would like right?
In the software development industry we got an equivalent for this. It is a set of rules that our ships and containers should follow. For that we got an organization called Cloud Native Computing Foundation and they present themselves as
The Cloud Native Computing Foundation (CNCF) hosts critical components of the global technology infrastructure. CNCF brings together the world’s top developers, end users, and vendors and runs the largest open source developer conferences. CNCF is part of the nonprofit Linux Foundation.
And they help define the concept of Cloud Native:
Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil.
The Cloud Native Computing Foundation seeks to drive adoption of this paradigm by fostering and sustaining an ecosystem of open source, vendor-neutral projects. We democratize state-of-the-art patterns to make these innovations accessible for everyone.
Which they write in several languages.
Yeah and this is basically the first chapter.
Building the goods (chapter 2)
From here the authors go into chapter 2 which is basically a small example of how you can create an application and deploy it in a (already running) kubernetes cluster. We can summarize the whole chapter to
- Create a dummy go web application (our goods)
- Create the dockerfile that will build the application (our container)
- Deploy it in kubernetes (put the dam thing on the ship)
The ship factory (chapter 3)
Ramming speed into chapter 3 and what we got? The story begins with an overall architecture of kubernetes (and believe me its complex). They discuss the pros and cons of a self hosted cluster versus a public cloud one. They build a compelling argument for the use of public clouds depending of course on your specific use case (bear in mind that both have pros and cons obviously).
From here the authors introduce to us the main contenders in the shipyard industry. And they present the following providers
- Google Kubernetes Engine
- Amazon Elastic Kubernetes Service and Amazon Elastic Container Service
- Azure Kubernetes Service
- Open Shift
- IBM Cloud Kubernetes Service
- Heptio Kubernetes Subscription
Some hybrid kubernetes solutions were also discussed and the following technologies/platforms revised
- Stackpoint
- Containership Kubernetes Engine
- Kops
- Kubespray
- TK8
- kubeadm
- tarmak
- Rancher Kubernetes Engine
- Puppet kubernetes module
- Kubeformation
- Amazon Fargate
- Azure Container Instances
And
which is a thorough tutorial how to manually install kubernetes.
The chapter ends with a battle of arguments for why you should have your own hosted kubernetes cluster and why you shouldn't. With the authors, comprehensively (economic reasons mainly), making a case for the latter. Bear in mind that this assumes a very specific set of premises that will hold or not depending on the company use case.
Operating the ship (chapter 4)
And finally, after some 50+ pages of reading we are ready for some kubernetes juice. So what are the goodies? Well in this chapter give an introductory presentation to kubernetes. The authors decided to jump immediately to one of the most core concepts in kubernetes the concept of deployment. They introduce the concept of pod and how deployments are responsible for schedule and supervise it. In a picture something along these lines
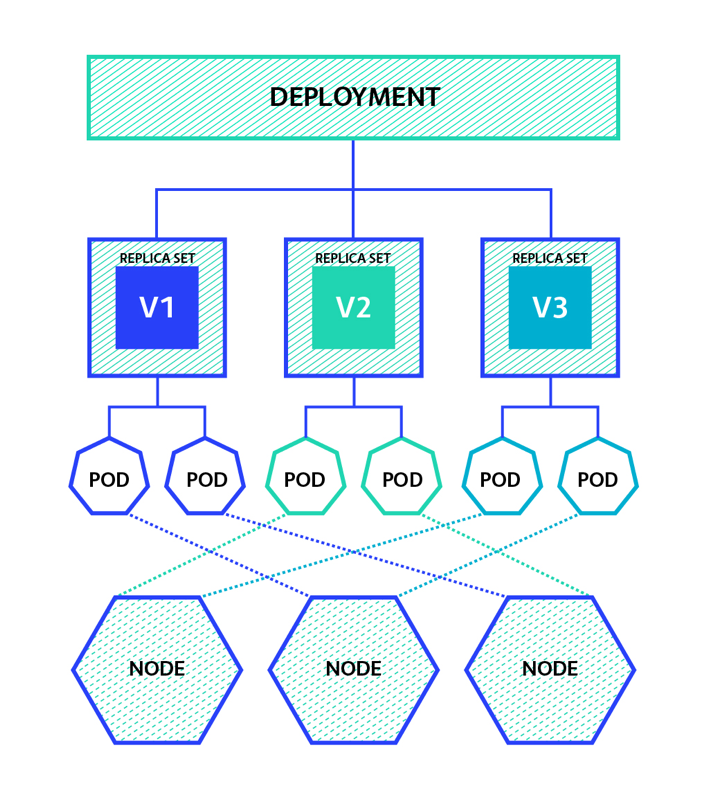
The Kubectl was introduced and some useful commands to manage the kubernetes cluster like
kubectl get deployments # Get installed deployments
kubectl describe deployments/<app_name> # Describe an installed deployment
kubectl apply -f k8s/deployment.yaml # Create a deployment by applying a yaml file with the kubernetes specification
kubectl port-forward service/<app_name> 9999:8888
From there they follow with the concept of services and finished the chapter by introducing Helm, also known as the kubernetes package manager.
Watch for your goods (chapter 5)
After an introductory presentation of the main functionalities of kubernetes was time for some time to discuss the after deployment. You have your application running, now what?! Actually several things need to be done, but the following two are kind of important in a kubernetes deployment
- Define quotas for resource usage regarding your application
- Monitor applications healthy
But first. Why resource quotas? Can't I just deploy and leave as is? Actually you can. But it turns out that if leaved alone applications can go wild. Kubernetes was designed to deploy hundreds os containers across several hundreds of nodes (machines where the containers run). If leaved alone these applications could start competing in a uncontrolled way for the computational resources and create havoc. Hence resource management. In kubernetes language these are called resource units and they can be of two types. Resource requests and Resource limits. Resource requests specify the minimum amount of resources needed for your application (aka pod) to be able for deployment. If the requests specified are not met the pod will not be schedule for deployment. On the other hand, related with the havoc problem mentioned previously, Resource limits are values we specify as the acceptable usage for our application. This don't means that if the application hits the threshold that will be immediately killed by the engine. It means that it is elected for removal if the whole cluster ends up in dark waters (meaning lacking of resources).
Aside from the resource units this chapter also revolves around giving kubernetes a means to check for your application sanity. And this is done via probes. And as usual there are several types
- Readiness probes
- Liveliness probes
and they are pretty self explanatory also. The first is a check you define that kubernetes use to decide if the pod is ready to join de cluster. The liveliness probe is a check that states if the pod is healthy. If not it will be killed and restart again. In an infinite loop.
And so it is. In a nutshell this is the gist of the chapter. Moving forward?
Sailing the boat (Chapter 6)
This chapter takes a step back from the developer point of view and dresses the operations guy shoes (hope this at least makes sense). What does this mean? Yeah you figure it out. Managing the cluster. Yes, like a car, kubernetes cluster will not manage itself (damn). And so the following was addressed and some best practices advised
- Capacity planning
- Nodes and instances
- Scaling up/down the cluster
- Overview over autoscalling, pros/cons
The rest of the chapter was much more interesting with an overview over the Kubernetes certification process the CNFC Certification

As expected a certification process defines a set of rules for which a compliant kubernetes solution must obey. As such a bunch of tools were created to help the process of validation and auditing. And so the following tools were discussed
After a brief overview over these projects/tools we shift the boat into Chaos Testing and the authors make some arguments in favor of it in the initial pages. The final of the chapter ends with another discussion about a set of tools that were designed to enable Chaos Testing in kubernetes
Deep waters (chapter 7)
After some spending some pages discussing the awesome topic of breaking the cluster apart with the previous Caos Tools the wind changes and we enter, suddenly, in a very deep geek chapter. This chapter is all hands on and the authors share some of the tooling they use and some more or less personal hacks they develop to enhance productivity. But, enough of mumbo jumbo.
First set of tricks are a set of very useful shell aliases. Yeah operating a kubernetes cluster with the tool kubectl is kind of a painful because of the inherent verbosity (as you can check on the link above). So these are some of sugar magic they use, and you (me) also should to avoid a keyboard breakdown.
alias k=kubectl
alias kg=kubectl get
alias kgdep=kubectl get deployment
alias ksys=kubectl --namespace=kube-system
alias kd=kubectl describe
If you are like me you'll probably will love this hacky shortcuts. The second advice was to shortcut the usual commands by their respective shortcuts
kubectl get po
kubectl get deploy
kubectl get svc
kubectl get ns
which, if you use the previous aliases can shortcut event more into
kg po
kg deploy
kg svc
kg ns
Aside from this neat hacks in this chapter the authors also presented us a practical technique that you can use to manage your kubernetes files. For instance, if for some reason you just want to know how an application was setup you can use kubectl to give the deployment manifest for you
kubectl run demo --image=repository/namespace:application --dry-run -o yaml > myapp.yaml
In the previous command we are using kubectl to run the demo container of a specific application in dry-mode. Dry-mode enable us to run the deployment without actually deploying it. At the same time we export the manifest into the stdout on yaml format. This is actually very handy because it enable us to see the kubernetes configuration for that application. We can, in this way reverse engineer, debug and fix it in a very easy way.
We can exploit this technique for already deployed applications with the following command
kubectl get deployments mydeployment -o yaml --export > mydeployment.yaml
Another handy practice is the use of diff command to validate your changes before actually commiting them to kubernetes
kubectl diff mydeployment.yml
The previous command should output a list of differences between the file and the already deployed version.
Log is another very usefull command
kubectl logs -f tiller-deploy-8478fc7f94-hbvbd -n kube-system
The previous command enable us to follow the log output of the tiller that is running on the cluster.
The rest of the chapter revolved around a set of hacky tools that were developed to ease even more the operational burden. Being them
Manage the goods with containers (chapter 8,9)
Chapter 8 and chapter 9 enter in a bit more of detail in the theme of running and managing the containers.
Chater 8 is divided in the following sections
- Containers and pods
- Container manifests
- Container security
- Volumes
- Restart policies
- Image pull secrets
Containers and pods
The first section clarifies the concepts of container and pod. This is important since these concepts are sometimes used interchangeably. In short a pod can be think of a unit of deployment that encompasses one or more containers. The confusion arises because most of the time, and for good reasons, the pod is composed by only one container.
Container manifests
Containers and pods need to be defined in kubernetes language. The definition of a pod and respective containers in kubernetes language is called a manifest. This section explains how to create manifests and some principles to guide the way we partition containers into pods. Some technical points are discussed. Concept of tag, resource request/limits and ports were revisited. However the most interesting points tackled were those regarding pull image policy, called imagePullPolicy. It is explained that you can define the pull of image with three different strategies
- Always - Basically will pull the image every time the pod is deployed
- IfNotPresent - Will pull from registry only when not found locally
- Never - Never pull the image
These options can become handy depending your use case.
Container Security
Most of the times we see containers running with full root permissions. However this entails a serious security risk which in the case of the enterprise can't be acceptable. So the authors try to convince you to write your pod manifests in a way that containers run with non-root permissions
containers:
- name: myapplication
image: namespace/application:tag
securityContext:
runAsUser: 1000
The previous snippet shows how we can achieve this by providing an attribute called securityContext with the value 1000. Apart from the runAsUser there is also
securityContext:
runAsNonRoot: true
readOnlyRootFilesystem: true
allowPrivilegeEscalation: false
which prevents users from escalating privileges and the concept of Capabilities that enable fine grained access to the privilege protected functionality
containers:
- name: myriskyapp
image: mynamespace/mydemo:mytag
securityContext:
capabilities:
drop: ["CHOWN", "NET_RAW", "SETPCAP"]
add: ["NET_ADMIN"]
Then we went into how to manage volumes in kubernetes and the manage policies available. By default kubernetes always restart the container as soon as it exits. However there is another policy that will only restart the container if it exits with a failure exit code. This can be handy if you want jobs instead of long running daemon applications. By enforcing the restart only when the exit code means failure you are able to restart jobs when they fail but also able to let them be when the job is a success.
Managing the pods
In this section we deal with the following
- Labels and Selectors
- Node affinity anti-affinity
- Kubernetes taints and toleration
- Pod Controllers
- Ingress resources
Hide the treasure (chapter 10)
After digging a little bit more deep in the kubernetes machinery the authors delve an entire chapter for a specific kubernetes primitive. Configuration and Secrets. When we create an application we usually create configurations as a way to dynamically change their behavior. ConfigMaps is kubernetes primitive we can use for this purpose. However not all configurations are created equal. Some configurations are a little bit more sensitive, and for practical reasons they need access policies in place to avoid non authorized people the access.
Back again to the traditional case. When we create an application we can have a set of configuration files we can apply. But, on the other hand, we can also apply the same set of configuration files the another binary version. So instead of a 1-1 relationship we actually have a more decouple relationship. Kubernetes team acknowledge this and enable a similar mechanism.
In kubernentes you create configuration maps with your configuration data and kubernetes gives you a way to attach it to a deployment. One ore more of it.
Behold, a configuration map
apiVersion: v1
kind: ConfigMap
metadata:
name: myAwesomeConfig
namespace: myAwesomeNamespace
data:
config.yaml: |
destroyTheWorld: false
conquerTheSeas: true
protocols:
- tcp
- udp
But you're right! We need somehow to use this in our deployment manifest.
spec:
containers:
- name: mycontainer
image: mynamespace/myimage:mytag
ports:
- containerPort: 6666
volumeMounts:
- mountPath: /myconfigs/
name: myAwesomeConfig-volume
readOnly: true
volumes:
- name: myAwesomeConfig-volume
configMap:
name: myAwesomeConfig
items:
- key: config
path: config.yaml
The same happens for secrets.
apiVersion: v1
kind: Secret
metadata:
name: mysecret
stringData:
magicWord: myultrasecretword
you have the same strategy to assign secrets into your deployment. But there is a caveat right? Remember that we should have all our infrastructure as code. This creates a problem. Does makes sense push into git a token with myultrasecretword as a secret? That's not very secret right? To solve this issue the authors present two approaches. One that makes use of a open source tool called sops and tools like GnuPG for private/public key cryptography, for keypair generation at least.
Another approach mentioned was a managed one based on external services like HashiCorp Vault
Protect the ship (chapter 11)
After the secret section on chapter 10 that introduced some concepts of information security in kubernetes we jump into chapter 11 that deals with kubernetes security key concept. The Role-Based Access Control also known as RBAC. According to the kubernetes engineering team this means
Role-based access control (RBAC) is a method of regulating access to computer or network resources based on the roles of individual users within an enterprise.
Here we are introduced to the concepts of Role and ClusterRole. The difference between Role and a ClusterRole is just the scope of the roles for which we can apply it. The Role can only be applied to a specific namespace while a ClusterRole is cross namespaces. That's why we don't see the namespace in the metadata field in the ClusterRole definition
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: default
name: pod-auth
rules:
- apiGroups: [""] # "" indicates the core API group
resources: ["pods"]
verbs: ["get", "watch", "list"]
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: secret-auth
rules:
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get", "watch", "list"]
Apart from the technical differences of Role and ClusterRole and how we use it with the concept of RoleBinding and also ClusterRoleBinding, the authors also give us an important principle for which we should manage the Authorization in Kubernetes
Make sure RBAC is enabled in all your clusters. Give cluster admin rights only to users who actually need the power to destroy everything in the cluster. If your app needs access to cluster resources, create a service account for it and bind it to a role with only the permissions it needs, in only the namespaces where it needs them.
Security, as we already know, is serious business. It is also usually neglected because it happens to difficult the usual process of software engineering. The software industry has a natural tendency to treat security, among other fields, as a second class citizen during the iterative process of software engineering. For this reason it is of uttermost importance to put in place process and tools to mitigate this misbehavior. And as we all know tools are usually better. The authors were sensible to this and spend some time in the chapter presenting some we can use to help ensure our cluster security. They presented the following
- Clair - Tool that does statical analysis to containers, checking security vulnerabilities
- Aqua - A security platform
- Anchore Engine - The Anchore Engine is an open source project that provides a centralized service for inspection, analysis and certification of container images. The Anchore engine is provided as a Docker container image that can be run standalone, or within an orchestration platform such as Kubernetes, Docker Swarm, Rancher, Amazon ECS, and other container orchestration platforms.
And regarding security that was it.
Security is good but having a backup plan is also an intelligent approach. And backups is exactly what the authors tackle after. If you spend some time exploring kubernetes architecture you'll find that etcd is core piece.

The main reason why etcd is so important is because it holds all the state of the cluster. So yeah, you lose this state and you loose the cluster, or at least you severely compromise it.
So you guessed it, we need to backup etcd state. As usual somebody else thought about this and, better yet, they created tool to help them with this. Fortunately they opensourced it. Its called Velero.
From their readme
Velero (formerly Heptio Ark) gives you tools to back up and restore your Kubernetes cluster resources and persistent volumes. You can run Velero with a cloud provider or on-premises. Velero lets you:
Take backups of your cluster and restore in case of loss.
Migrate cluster resources to other clusters.
Replicate your production cluster to development and testing clusters.
And that was all for chapter 11
Deploy that ship (chapter 12)
If you take time to see a typical setup of a kubernetes application you'll notice that one problem we have with the manifests is that they suffer from some problems
- They are verbose
- They tend to have lots of repeated blocks of properties
- Not easy to reuse
To address these points, and some others, some tools were developed. One of such tools, as we already mentioned, is Helm and this chapter spend some time analyzing the overall structure of Helm Charts and how you can use the template engine to parametrize the charts as a way to reuse it.
Helm is not the only player in town. Other tools exist to do more or less the same.
- Ksonnet - ksonnet is a configuration management tool for Kubernetes manifests. The goal of ksonnet is to improve developer experience by providing options beyond writing YAML or text templating.
- Kapitan - Kapitan is a tool to manage complex deployments using jsonnet, kadet (alpha) and jinja2. Use Kapitan to manage your Kubernetes manifests, your documentation, your Terraform configuration or even simplify your scripts.
- Kompose - kompose is a tool to help users who are familiar with docker-compose move to Kubernetes. kompose takes a Docker Compose file and translates it into Kubernetes resources.
- Ansible
Apart from the developing of manifests it is also important to have a way to validate them. For that we also have some tools
- Kubeval kubeval is a tool for validating a Kubernetes YAML or JSON configuration file. It does so using schemas generated from the Kubernetes OpenAPI specification, and therefore can validate schemas for multiple versions of Kubernetes
And with this we end the chapter 12. This chapter is specially nice for guys that like to explore new tools and specially for those who manifest management is painful.
Daylife of the a sailor (chapter 13)
If on chapter 12 we were presented with a battery of tools to help us develop kubernetes manifests. In chapter 13 we face another critical aspect of kubernetes automation development process. How to implement a quick feedback loop when developing our manifests. The traditional way of doing things would be
- Develope your application
- Create your kubernetes manifests
- Deploy your application via the built manifests
So in order to be able to quickly develop kubernetes manifests you need a way to test your manifests against a kubernetes cluster. But what if you don't have one because you're not physically connected to a cluster or simply don't want to test it on a real cluster?
What we need is tools that enable us local development as a way to debug and iterate quicker.
For this mission the following tools were presented
After a quick overview over these technologies we jump into another important topic. Deployment strategies. There is a vast literature on the topic, and with a quick google search you find articles like this one or this one that can introduce to the topic. This section of the book explore this in kubernetes context and explain how you can implement the following strategies
The rest of the chapter explains how you can use helm to manage migrations with the use of helm hooks.
The fishing loop (chapter 14)
If chapter 13 was all about the deployment strategies and more importantly how you can implement them in a kubernetes environment. Chapter 14 follow into the Continuous Deployment arena. The authors delve into the nuts and bolts of CD and they approach the main tools currently in existence for the kubernetes realm.
- Apache Jenkins
- And more specifically for Kubernetes the Apache Jenkins X
- Drone
- Google Cloud Build
- Concourse
- Spinnaker
- For which the tool authors created a free ebook for you to delve deep
- GitLabCI
- CodeFresh
- Azure Pipelines
Above are the main contenders in existence, as the current state of art.
For the deployment to be possible there is yet a missing piece. The previous tools are only able to deploy binaries, in the case of kubernetes these binaries are linux containers. Linux containers need to exist somewhere else. The services responsible to hold the binaries are usually known as container registries. Apart from the process of deploying a container in the kubernetes cluster there is also the process of compiling it from source code and pushing it into the registry, this relates with Continuous Integration. To solve this problem several technologies were analysed.
- DockerHub
- A public docker container registry
- GitKube
- Gitkube is a tool for building and deploying Docker images on Kubernetes using git push.
- FluxCD
- A tool that manages the state of the cluster based on the current git and registry state.
- Keel
- Kubernetes Operator to automate Helm, DaemonSet, StatefulSet & Deployment updates
And this is pretty much the gist of the chapter.
Measure your position (chapter 15 and 16)
Chapters 15 and 16 are the last ones of the book. Sad right? These last two chapters deal with the operational part of the application. The book was written in an incremental way and also in a somewhat chronological view. We start looking into the dawn of computer systems and the similarities between currently cloud solutions and the good old days of time shared computing. Then we dig into the anatomy of a web application, the rise of microservices all the operational burden that rises from there. We were introduced to the devops movement and the advantages we can rip from this way of working and so on. Finally we got our application up and running live. So what? My work is done? I'm out? Well not so fast. After your application is up and running you need to ensure that it is doing what is supposed to. You see, all this journey had a very defined goal. An optimized way to build and manage software solutions at the highest quality. The problem is that quality is not an end state but actually a continuos process of monitoring and refinement. This last two chapters deal with the monitoring part of it.
And this lead us to the idea of Observability . This is not a new concept and you can find their roots in the field of control theory with the exact same name. Unsurprisingly the definition from control theory can be applied in the world of software development. Some articles defend exaclty this.
But, in this modern context, what do we mean, in practice, by observability?
There is not a unique view over the concept. So it is ok if you find several other differente definitions, but broadly I would say
In its most complete sense, observability is a property of a system that has been designed, built, tested, deployed, operated, monitored, maintained, and evolved in acknowledgment of the following facts:
No complex system is ever fully healthy.
Distributed systems are pathologically unpredictable.
It’s impossible to predict the myriad states of partial failure various parts of the system might end up in.
Failure needs to be embraced at every phase, from system design to implementation, testing, deployment, and, finally, operation.
Ease of debugging is a cornerstone for the maintenance and evolution of robust systems.
If you have curiosity and want to dig a little bit more into the concept of observability you can start with this qcon presentation and this observability primer
If you take some time to check the field you'll notice that usually you'll end up with three main subfields
The authors spend most of time in the metrics and traceability subfields. In the metrics section they presented two interesting methods that you can use to devise better your metrics.
There are plenty of literature you can explore regarding this two patterns.
This book, as you can see, was an awesome ride. The amount of useful information and interesting principles, methodologies and techniques are well worth the money you pay for the book. Hope you give this book a try and enjoy it as well as I did. And again a very thank you for both the authors.